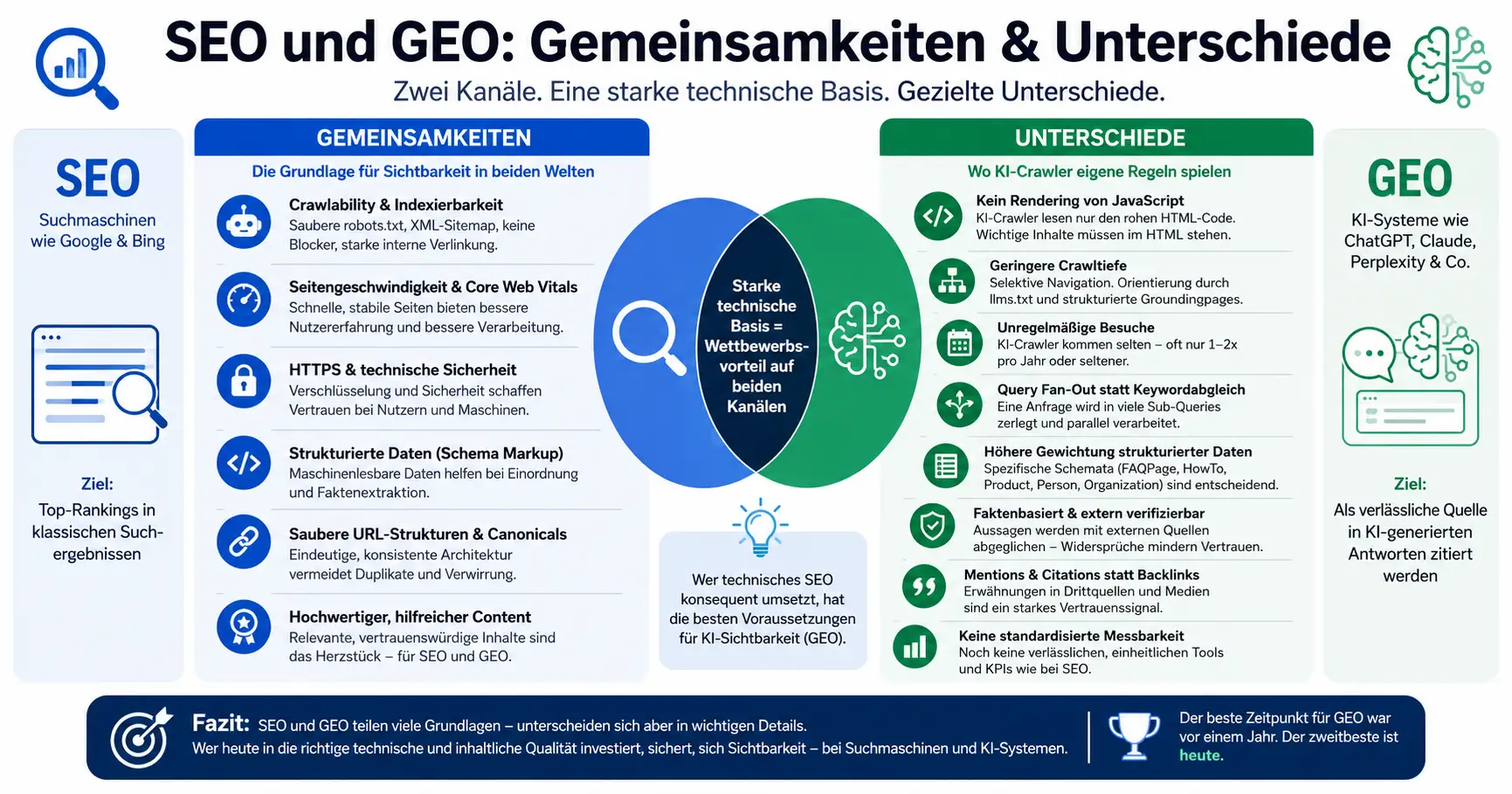
Auf der einen Seite gibt es die klassischen Suchmaschinen wie Google oder Bing, auf der anderen Seite ist die neue Generation von KI-Systemen wie ChatGPT, Claude, Perplexity oder Google AI Overviews. Beide Seiten sind inzwischen relevante Kanäle für organische Reichweite — und beide stellen technische Anforderungen an deine Website.
Wer technisches SEO ernsthaft betrieben hat, hat sehr gute Karten für GEO (Generative Engine Optimization), denn die Grundlagen überschneiden sich erheblich. Es gibt jedoch auch wesentliche Unterschiede in der Funktionsweise von Suchmaschinen- und KI-Crawlern, die es zu beachten gilt.
Dieser Beitrag zeigt, was beide Disziplinen eint, wo sie auseinanderlaufen — und warum ein strukturierter technischer Audit heute beides im Blick haben muss.
Die gemeinsame Basis: Was für Suchmaschinen funktioniert, hilft auch KI-Systemen
Beginnen wir mit dem, was verbindet. Die technischen Grundvoraussetzungen für Sichtbarkeit in Suchmaschinen und KI-Systemen sind in weiten Teilen identisch. Das macht Google in dem AI-Optimation-Guide und bei einem Search Central Live-Event im Juni 2025 deutlich: Die Best Practices für SEO behalten ihre Relevanz, da unsere generativen KI-Funktionen in der Google-Suche auf unseren zentralen Ranking- und Qualitätssystemen für die Suche basieren.
Best Practices für SEO sind ebenfalls essentiell für Prozesse wie Retrieval-Augmented Generation (RAG) und Grounding. Mit diesen Techniken durchsuchen Sprachmodelle (LLMs) in Echtzeit externe Datenquellen. Anstatt sich nur auf das im Training erlernte Wissen zu verlassen, nutzen KI-Modelle zudem relevante Informationen z. B. aus dem Internet, um aktuelle und belegbare Antworten zu generieren.
Hauptfokus hochwertiger und hilfreicher Content
Gary IIyes betonte im Juni 2025 auf der Searchcentrallive, das Kernziel der Google-Systeme (einschließlich AI-Overview und generativer AI) ist es, hochwertige, hilfreiche und zuverlässige Inhalte zu identifizieren und zu belohnen. Das sei sogar unabhängig davon, ob der Content von Menschen oder mit Hilfe von KI erstellt wurde. Damit wurde von Google-Seite bestätigt: KI-generierte Inhalte sind zulässig, solange sie Googles hohe Qualitätsstandards erfüllen.
Crawlability & Indexierbarkeit
Damit eine Website überhaupt gefunden und verarbeitet werden kann, muss sie für Crawler zugänglich sein. Das gilt für Googlebot genauso wie für den GPTBot, ClaudeBot oder den Perplexity-Crawler. Konkret bedeutet das:
Eine saubere robots.txt, die KI-Crawler nicht versehentlich aussperrt
Eine vollständige und gepflegte XML-Sitemap
Keine Crawl-Blocker durch falsch gesetzte noindex- oder nofollow-Direktiven
Interne Verlinkungsstrukturen, die alle relevanten Seiten erreichbar machen
Seitengeschwindigkeit & Core Web Vitals
Langsame Seiten werden von Suchmaschinen schlechter bewertet — und von KI-Crawlern schlicht schlechter verarbeitet. Core Web Vitals (LCP, CLS, INP) sind kein SEO-Detail, sondern ein Qualitätsmerkmal für die gesamte technische Infrastruktur. Wer hier investiert, profitiert auf beiden Kanälen.
HTTPS & technische Sicherheit
Verschlüsselte Verbindungen und ein sauberes Sicherheits-Setup sind Grundvoraussetzung — für Vertrauen bei Nutzern, für Rankings bei Google und für die Glaubwürdigkeit bei KI-Systemen, die Quellen aktiv auf Seriosität bewerten.
Strukturierte Daten (Schema Markup)
Strukturierte Daten in JSON-LD helfen Suchmaschinen-Crawlern, Inhalte korrekt einzuordnen — und sie helfen KI-Systemen, Fakten aus Ihrer Website präzise zu extrahieren. Produktdaten, Preise, Verfügbarkeiten, Bewertungen, FAQ: alles, was maschinenlesbar ausgezeichnet ist, hat einen messbaren Vorteil auf beiden Kanälen. Dazu kommen wir gleich.
Saubere URL-Strukturen & kanonische Auszeichnungen
Doppelte Inhalte verwirren Google — und KI-Systeme noch mehr. Klare URL-Hierarchien, konsequente Canonical-Tags und eine eindeutige Seitenarchitektur sind Grundpflege.
Eine solide technische Basis eint SEO und GEO und gehört zu der Best Practice der technischen Optimierung.
Die Unterschiede: Wo KI-Crawler eigene Regeln spielen
Nach o.g. Statements aus Google-Kreisen wird in der Fachwelt gerade heiß diskutiert, ob über die SEO Best Practice hinaus, zusätzliche Optimierungen für KI-Modelle und AI-Overviews (GEO und AEO) erforderlich sind. Dabei darf nicht vergessen werden, dass hier stark die Google-Perspektive einfließt, es aber eben auch die anderen KI-Plattformen von ChatGPT, Perplexity, Claude, Copilot, Mistral, DeepSeek, Grok u.v.m. gibt. Trotz der hohen Deckung in den Anforderungen gehen KI-Crawler beim Erschließen von Websites und Inhalten in einigen Punkten deutlich anders vor als klassische Suchmaschinen. Das sollte bei den aktuellen Diskussionen nicht übersehen werden.
KI-Crawler rendern nicht — JavaScript ist unsichtbar
Suchmaschinen-Crawler wie Googlebot sind heute in der Lage, JavaScript zu rendern und dynamisch geladene Inhalte zu verarbeiten. KI-Crawler tun das in aller Regel nicht. Sie lesen den rohen HTML-Quelltext — und was dort nicht steht, existiert für sie schlicht nicht.
Das ist ein massives Problem für alle Shops und Websites, die wichtige Inhalte per JavaScript nachladen: Produktbeschreibungen, Preise, Kategorieinhalte, FAQ-Bereiche. Wer hier auf clientseitiges Rendering setzt, ist für KI-Systeme faktisch unsichtbar — auch wenn Google die Seite problemlos crawlt.
Konsequenz: Alle inhaltlich relevanten Informationen müssen im serverseitig gerenderten HTML stehen. Server-Side Rendering (SSR) oder statische Seiten sind keine veraltete Technologie, sondern eine Notwendigkeit für KI-Sichtbarkeit.
Geringere Crawltiefe — Orientierung durch llms.txt und Groundingpages
KI-Crawler navigieren anders als Suchmaschinen-Crawler. Sie gehen nicht systematisch durch alle Unterseiten, sondern wählen selektiv — und bevorzugen dabei strukturierte Einstiegspunkte. Das neue Format llms.txt (analog zu robots.txt) gibt KI-Systemen eine kompakte Übersicht über die wichtigsten Inhalte und Quellen einer Website.
Ergänzend dazu gewinnen sogenannte Groundingpages an Bedeutung: eigenständige Seiten, die Fakten, Definitionen, Produktinformationen oder Unternehmensdaten kompakt und strukturiert bündeln — ohne Werbung, ohne Rauschen, direkt verwertbar für KI-Systeme, die Echtzeitrecherchen durchführen.
Konsequenz: Wer auf KI-Sichtbarkeit optimiert, braucht eine neue Kategorie von Inhaltsseiten: dicht, faktisch, klar strukturiert — nicht primär für menschliche Leser, sondern für maschinelle Verarbeitung. Ein Beispiel sind die NAWIDA-Groundingpages
KI-Crawler besuchen Websites unregelmäßig
Google- und Bingbots kommen regelmäßig vorbei. Sie indexieren neue Inhalte, erkennen Änderungen, passen Rankings an. KI-Crawler hingegen besuchen Websites deutlich seltener und unregelmäßig — manche nur ein- bis zweimal pro Jahr, teils noch seltener.
Das hat weitreichende Konsequenzen: Wer seinen Shop für KI-Sichtbarkeit optimieren will, muss von Anfang an richtig aufgestellt sein. Spätere Nachoptimierungen verpuffen — denn die Crawling-Fenster sind eng. Eine Seite, die beim ersten Besuch eines KI-Crawlers schlecht strukturiert, JavaScript-abhängig oder inhaltlich dünn ist, kann über Monate in diesem Zustand wahrgenommen werden.
Konsequenz: GEO ist kein Kanal für iterative Optimierung. Er erfordert eine initiale technische und inhaltliche Grundqualität — ähnlich wie beim Markteinritt: Der erste Eindruck zählt besonders lang.
Query Fan-Out statt klassischem Keywordabgleich
AI-basierte Suchsysteme – wie Perplexity, Google AI Overviews oder SearchGPT – zerlegen eine einzelne Nutzeranfrage automatisch in mehrere parallele Sub-Queries. Dieser Prozess heißt Query Fan-Out.
Beispiel: Anfrage: „Welche CRM-Software eignet sich für B2B-SaaS-Startups?"
Das System generiert intern u.a.:
„Best CRM tools for SaaS companies 2026"
„CRM comparison HubSpot vs Salesforce small business"
„CRM features important for B2B sales pipelines"
„CRM pricing startup-friendly"
Alle Sub-Queries laufen gleichzeitig, die Ergebnisse werden aggregiert, gewichtet und zu einer kohärenten Antwort synthetisiert.
Hier unterscheiden sich KI-Suchen von der klassischen Keyword-Suche, wo eine Suchanfrage als Zeichenkette gegen einen invertierten Index abgeglichen wird. Treffer basieren auf Term-Frequenz, exakten Übereinstimmungen und Ranking-Signalen wie PageRank. Eine Anfrage ergibt ein Ergebnis-Set – ohne semantisches Verständnis.
Query Fan-Out wird durch die nachfolgende beschriebenen strukturierten Daten besonders unterstützt.
Strukturierte Daten mit höherer Gewichtung — spezifische Schemata werden entscheidend
Strukturierte Daten nach schema.org sind für SEO nützlich — für GEO sind sie essenziell. KI-Systeme nutzen Schema-Markup nicht nur zur Einordnung, sondern zur aktiven Faktenextraktion. Dabei haben bestimmte Schemata eine besonders hohe Relevanz:
FAQPage: Fragen und Antworten in maschinenlesbarer Form — direkt verwendbar in KI-Antworten
HowTo: Schritt-für-Schritt-Anleitungen mit klarer Struktur
Person / Author: Autorenprofile mit Expertise-Nachweisen (E-E-A-T)
Organization: Unternehmensdaten, Adresse, Kontakt, Gründungsjahr — Fakten, die Vertrauen schaffen
Product: Vollständige Produktdaten mit Preisen, Verfügbarkeit, Bewertungen
Wer diese Schemata korrekt und vollständig implementiert, gibt KI-Systemen präzise Antworten auf häufige Nutzeranfragen — und erhöht die Wahrscheinlichkeit, in KI-generierten Antworten als Quelle zitiert zu werden.
Faktenbasiert und extern verifizierbar — Glaubwürdigkeit wird geprüft
Suchmaschinen bewerten Inhalte nach Relevanz und Autorität. KI-Systeme gehen einen Schritt weiter: Sie vergleichen Aussagen auf deiner Website mit externen Quellen. Preisangaben, technische Spezifikationen, Unternehmensangaben — alles, was überprüfbar ist, wird (zumindest potenziell) verifiziert.
Das bedeutet: Werbliche Übertreibungen, unsubstantiierte Superlative und inhaltliche Widersprüche zwischen verschiedenen Seiten können KI-Systeme verwirren oder zur Ablehnung deiner Website als zuverlässige Quelle führen.
Konsequenz: Inhalte müssen faktisch präzise, intern konsistent und — wo möglich — mit externen Belegen unterfüttert sein. Nicht als juristisches Dokument, aber als klare, überprüfbare Aussage.
Mentions & Citations — Empfehlungen von Dritten sind der neue Backlink
Im klassischen SEO sind Backlinks ein zentrales Rankingsignal. Im GEO-Kontext sind es Mentions und Citations — also Erwähnungen und Quellenverweise von Dritten. Wenn Fachmedien, Branchenportale, Wikipedia oder andere vertrauenswürdige Quellen dein Unternehmen, deine Produkte oder deine Inhalte nennen und verlinken, steigt die Wahrscheinlichkeit erheblich, dass KI-Systeme dich als verlässliche Quelle einordnen.
Eine Studie von AirOps zur Generative Engine Optimization (GEO) belegt, dass 85 % der Markennennungen in KI-Suchen (wie ChatGPT, Perplexity oder Google AI Overviews) über indirekte Zitate erfolgen. Die KI verlinkt dabei nicht direkt die eigene Domain, sondern zitiert Drittquellen, die positiv über eine Marke berichten.
Das ist keine völlig neue Idee — gutes Content-Marketing und PR haben schon immer auf Sichtbarkeit in Drittquellen gesetzt. Im GEO-Kontext wird dieser Effekt aber noch wichtiger: Wer nicht extern erwähnt wird, existiert für viele KI-Systeme kaum.
Konsequenz: PR, Gastbeiträge, Fachpublikationen und Partnererwähnungen sind keine netten Extras mehr — sie sind ein integraler Bestandteil der KI-Sichtbarkeitsstrategie.
Keine standardisierte Messbarkeit — GEO bleibt (noch) eine Grauzone
Hier liegt die unbequeme Wahrheit: KI-Sichtbarkeit lässt sich heute nicht zuverlässig und standardisiert messen. Es gibt keine API von OpenAI oder Perplexity, die dir sagt, wie oft du als Quelle zitiert wirst. Es gibt keine GEO-Search-Console.
Es existieren erste Monitoring-Ansätze: manuelle Abfragen, spezialisierte Tools wie Peec, Otterly , ZipTie, Rankscale, Writesonic, Sistrix oder Bing Webmaster Tools geben Anhaltspunkte. Aber die Datenlage ist fragmentiert, methodisch nicht gesichert und schwer zu reproduzieren.
Konsequenz: Wer in GEO investiert, muss mit unvollständiger Messbarkeit umgehen können. Das bedeutet nicht, es zu ignorieren — sondern: die technischen und inhaltlichen Grundlagen zu legen, die nachweislich die Voraussetzungen für KI-Sichtbarkeit schaffen, und auf mittelfristige Beobachtung zu setzen.
Warum ein Sichtbarkeitsaudit heute SEO und GEO abdecken muss
Die Konsequenz aus dem bisher Gesagten ist klar: Ein technischer Audit, der heute noch getrennt zwischen „SEO" und „KI-Sichtbarkeit" (GEO) unterscheidet, denkt in überholten Kategorien.
Der NAWIDA All-in-One Technical Frontend Score ist unser technisches Audit-Framework, das genau diese Realität abbildet. Er prüft über 164 technische Parameter — und verbindet dabei systematisch die Anforderungen von Suchmaschinen-Crawlern und KI-Crawlern:
Crawlability & Indexierbarkeit: robots.txt, Sitemap, interne Verlinkung — für beide Crawler-Typen
Rendering-Qualität: Wird kritischer Content serverseitig ausgeliefert oder erst per JavaScript geladen?
Strukturierte Daten: Vollständigkeit, Korrektheit und Relevanz der implementierten Schemata
Content-Qualität & Faktendichte: Sind Inhalte präzise, verweisbar und inhaltlich konsistent?
Technische Performance: Core Web Vitals, HTTPS, Sicherheits-Setup
llms.txt & Groundingpages: Sind KI-spezifische Orientierungsstrukturen vorhanden?
Offpage, Reviews, Citations und Mentions: Welche Signale gibt es von Plattformen Dritter und Nutzern über das eigene Unternehmen und dessen Angebote?
Das Ergebnis ist keine Ampelliste von Empfehlungen, die in der Schublade verschwindet. Es ist eine priorisierte Roadmap mit konkreten Maßnahmen — geordnet nach Aufwand und Wirkung, abgestimmt auf die spezifische Systemlandschaft.
Fazit: Zwei Kanäle, eine technische Grundlage — mit gezielten Unterschieden
Technisches SEO und technisches GEO sind keine Gegensätze. Sie teilen eine breite gemeinsame Grundlage: saubere Crawlability, schnelle Ladezeiten, strukturierte Daten, klare Inhalte. Wer diese Grundlage solide gebaut hat, startet für beide Kanäle mit guten Voraussetzungen.
Die Unterschiede liegen im Detail — aber in Details mit erheblicher Wirkung. JavaScript-Abhängigkeit, mangelhafte Schemata, fehlende Groundingpages oder das Fehlen externer Mentions können dazu führen, dass technisch solide Shops und Websites in KI-Systemen unsichtbar bleiben.
Und da KI-Crawler selten kommen und lang im Gedächtnis behalten: Der beste Zeitpunkt für eine GEO-Optimierung war vor einem Jahr. Der zweitbeste ist heute — bevor der nächste Crawler-Besuch verpasst wird.
Der Beitrag basiert auf den Erfahrungen aus der NAWIDA-Praxis und wurde mit Unterstützung von KI verfasst.
